Reflections on the SuperComputing Conference (SC24): The Accelerating Tide of AI in 2024
Posted by Frank Yang on Dec 2, 2024

Artificial Intelligence (AI) has remained at the forefront of innovation and attention throughout 2024, driving transformative developments across industries. Nvidia, the powerhouse behind much of AI's progress, has accelerated the pace of its product releases, introducing groundbreaking iterations at an unprecedented rate. At SC24, Nvidia’s GB200 NVL72, compute tray, and switch tray attracted lots of visitors.
Nvidia’s advancements have introduced a flood of new terms and the emergence of myths, which have caused a mix of excitement and confusion. xAI built its AI supercomputer based on the Nvidia’s DGX H100 system. Meta has been using Nvidia H100 GPUs to train its Llama4 AI model. Both projects applied 100,000 or more GPUs. For better understanding, I have summarized the key generations of Nvidia’s GPU architecture and their corresponding systems in the chart below.
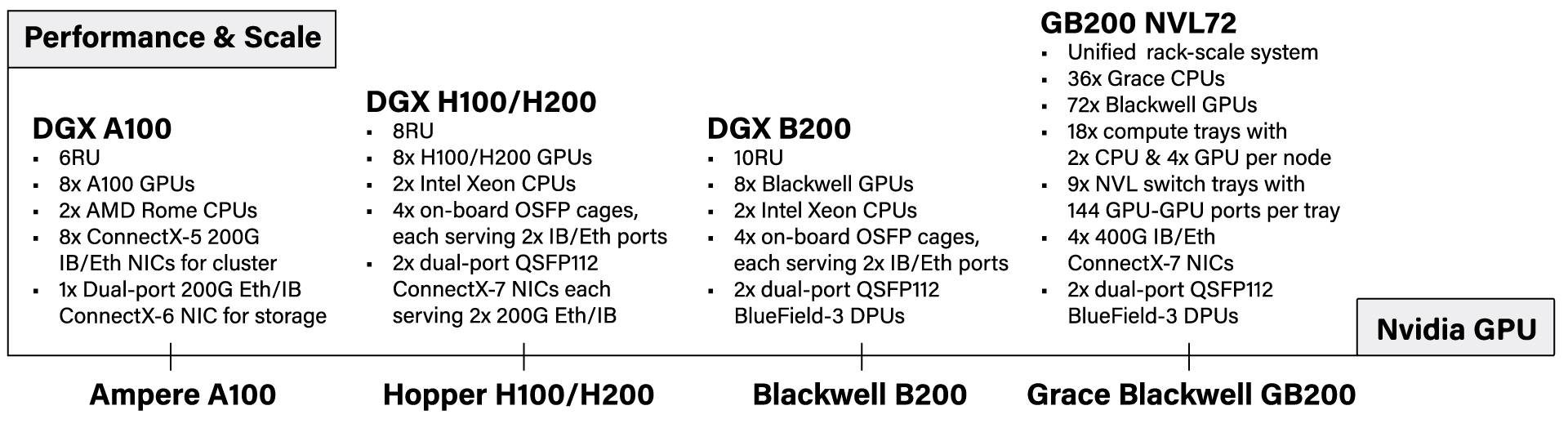
The chart highlights a key point: at the node level, the ratio of GPUs to network ports is 1:1. This indicates that each GPU is paired with a single network port. Since a network port requires an optical transceiver, we can conclude that each GPU is effectively matched with an optical transceiver at the compute node level. It’s important to note that the network port mentioned here is not an NVLink port.
While the performance and scale of GPUs have advanced with each generation, cost has increased. Now, the deployment of 100,000 GPUs is limited to a small group of organizations with substantial resources. But is larger scale and better performance the only path forward for AI? I believe AI innovations offer immense opportunities for smaller companies, particularly in domain-specific models that prioritize affordability and scalability, as shown in the chart below.
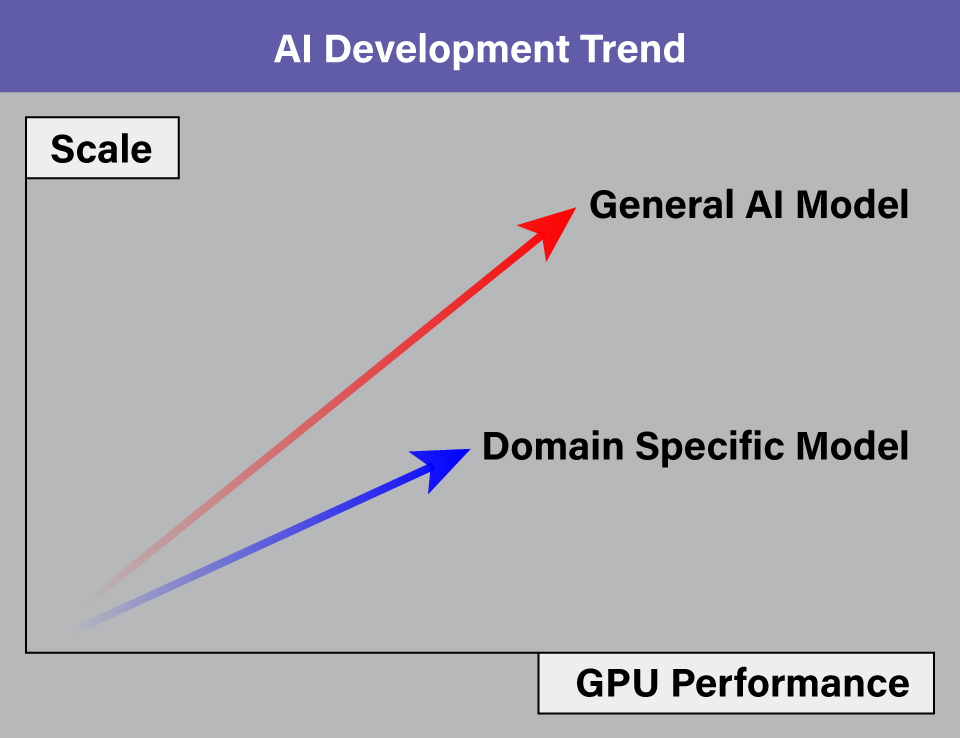
Pre-trained general AI models like GPT-4 and BERT are expected to continue evolving toward larger scales and higher performance. In contrast, fine-tuned domain-specific models, such as AlphaFold and Deep Patient, may chart a different course—prioritizing smaller scales while delivering exceptional performance in specialized applications.
One of the most frequently heard words at SC24 was "acceleration". In AI computation, acceleration is a crucial aspect that enables vast datasets and complex models to run faster, scale broader, and operate more efficiently. Acceleration represents one of the most significant advantages AI solutions can offer. By implementing effective acceleration strategies, domain-specific AI models can deliver the precise intelligence required for their specific applications.
Arista’s new Distributed Etherlink System (DES) also caught my attention. DES features two components: a smaller box for the leaf and a larger box for the spine, connected by the distributed Etherlink fabric. This system supports structured fiber cabling connectivity and 400/800GbE pluggable optics. The open fabric architecture enhances flexibility and scalability, making it particularly well-suited for AI networks. DES could prove highly relevant for networking in domain-specific AI models.
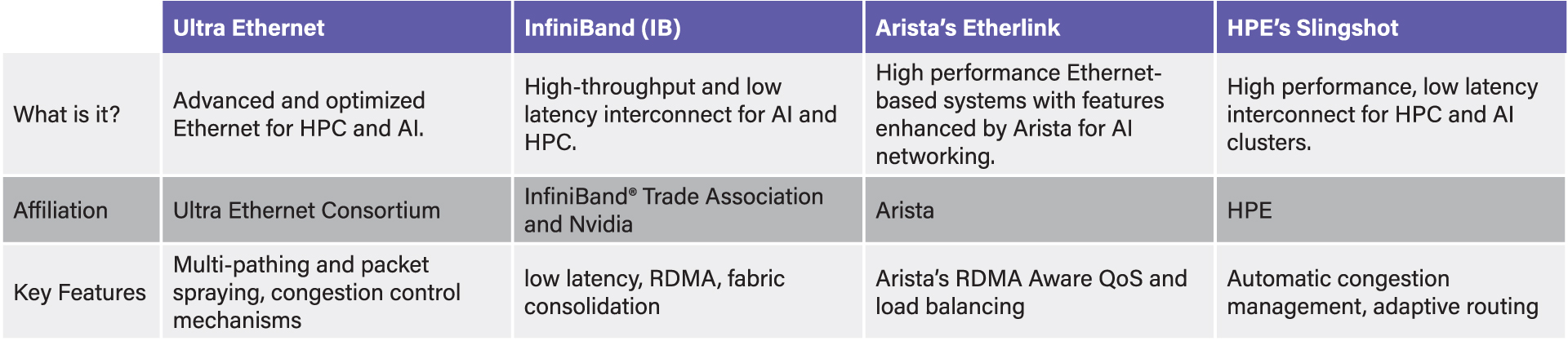
The technology industry is seeing the emergence of multiple options for AI networking, including Ultra Ethernet, HPE’s Slingshot, and Arista’s EtherLink, in addition to the established choice of InfiniBand. This growing diversity is encouraging, offering customers greater flexibility in choosing solutions that best fit their needs.
Approved Networks, a brand of Legrand, is dedicated to supporting customers in meeting their AI needs. Discover the range of solutions we offer by contacting our representatives at 800-590-9535 or visit us at ApprovedNetworks.com.